도입
머신러닝을 이용한 예측 모델에는 데이터셋 내의 값들이 시간에 따라 달라지는 시계열 데이터(time series)를 다루는 문제도 포함된다. 대표적인 예로 주식의 차트를 들 수 있다. 시가/종가가 매일 달라지는 것이 바로 시간에 따른 주식 가격의 변화를 시간순으로 축적한 것이다. 또한 채소 가격의 변화라든가 지구의 평균 온도의 변화도 시계열 분석의 대상이 될 수 있다. 최근에는 효율적인 교통 신호 시스템 구축을 위해 교통량의 추이를 분석하는 연구에도 시계열 분석법이 활발히 사용되고 있다.
이런 시계열 데이터의 가장 큰 특징은 바로 값들 사이에 어떤 상관관계가 존재한다는 것이다. 풀어서 얘기하자면, 가깝게는 어제의 값이 오늘의 값에 영향을 주고, 조금 더 길게는 과거의 패턴이 현재 혹은 미래의 값을 결정하는데 영향을 주는 것이다. 이런 특징은 시계열 분석을 하는 데 있어 기존의 서로 독립적인 값들에 대한 머신러닝 적용과는 약간은 다른 방법을 필요로 하게 된다.
시계열 분석에서 주로 다루는 문제는 과거의 패턴을 분석하여 미래의 값을 예측(forecasting)하는 것이다. 여기에서 시간순으로 만들어진 패턴이 중요하기 때문에 모델 트레이닝을 위해 데이터를 앞 뒤로 섞거나 랜덤하게 뽑는 일을 할 수 없다. 따라서, 어느 시점을 기준으로 이전 데이터는 훈련용, 이후는 검증용으로 순차적(sequential)인 방식으로 나누어야 한다. 역으로 말하자면, 시계열 분석의 목적이 과거의 값을 맞추는 것이 아니기 때문에 훈련과 검증 그룹의 순서가 시계열에서 바뀔 수 없다는 것이다. 시간순과 관계없이 새로운 값을 예측하는 것은 prediction이라고 할 수 있고, 이것은 forecast과 구분된다. 이런 차이는 시계열 예측 모델의 교차검증 (cross validation)을 하는데 중요한 점이기 때문에 기억해 두어야 한다.
이 포스팅을 시작으로 시계열 예측 모델 (time series forecasting model)에 대해서 정리해 보고자 한다. 인터넷에서 구할 수 있는 데이터를 선택해 분석하기 좋은 형태로 다듬는 것으로부터 시작해, 시계열 데이터에 적용할 수 있는 교차검증 방법 및 GridSearch를 통해 최적의 모델을 골라내는 것을 살펴보고, 마침내 몇 가지 대표적인 시계열 예측 모델들의 적용까지 해 볼 계획이다.
Import dataset
인터넷에서 구할 수 있는 open power system data를 다뤄 보도록 하자. 시계열 분석에 대한 포스팅에서 자주 사용되는 데이터셋이다.
import pandas as pd
url='https://raw.githubusercontent.com/jenfly/opsd/master/opsd_germany_daily.csv'
data = pd.read_csv(url,sep=",")
display(data)
url을 통해 데이터를 받아 pandas dataframe을 저장하여 출력해 본다.

컬럼의 개수와 각 컬럼의 타이틀을 확인한다.
for i, col in enumerate(data.columns):
print(i, col)총 다섯 개의 컬럼이 있고 그중 첫 번째 컬럼이 Date로 시간을 기록한 것이다.

또한, 각 컬럼의 어떤 데이터 타입인지 확인해 본다. Date를 제외한 모든 컬럼이 실수형 데이터를 기록한 것이다.
data.dtypes
반면, Date는 문자열 타입으로 기록되어 있다.
print(data['Date'][0], type(data['Date'][0]))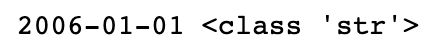
이것을 pandas에서 제공하는 datetime 포멧으로 바꾸어 준다.
# converting data to correct format
data['Date'] = pd.to_datetime(data['Date'])
display(data)이렇게 변환하는데는 두 가지 장점이 있다.
1. 시계열 데이터를 plot 할 때 x축의 label이 자동으로 되어 그림의 로딩 시간이 빨라진다. 스트링으로 plot 하면 로딩이 아주 느려진다.
2. 데이터 resampling이 용이하게 된다. 즉, weekly, monthly, yearly 단위로 데이터를 손쉽게 구분하여 분석할 수 있다.
따라서 포멧 변환을 반드시 해주도록 한다.

변환 후 Date의 데이터 타입이 달라진 것을 확인한다.
# check data types of columns
print(data.dtypes)
다음으로 할 것은 date를 dataframe의 index로 지정해주는 것이다. 시간은 종속변수가 아니기 때문에 index로 지정하며 컬럼에서 제외해 주는 것이다. 이렇게 하면 컬럼수를 줄일 수 있을 뿐만 아니라, 추후에 전체 데이터에서 target 데이터를 구분하는데도 용이하게 된다.
# set 'date' as the index of dataframe
data = data.set_index('Date')
display(data)다음과 같이 데이터가 재편된다.

Date가 컬럼 리스트에서 빠진 것을 확인할 수 있다.
data.columns
Cleaning dataset
위 과정에서 데이터를 출력하면서 Nan이 많은 것을 보았을 것이다. 이것은 측정이 되지 않은 값이므로 분석에는 필요 없는 데이터이다. 그럼 전체 데이터에서 nan값이 얼마나 있는지 확인해보자.
data.isna().sum()각 컬럼별로 몇 개의 nan이 있는지 보여준다. Consumption에는 0이지만 다른 컬럼에서 상당히 많이 발견된다.

nan이 하나라도 포함된 열(row), 즉 날짜의 데이터는 모두 삭제해야 한다. 그러니까 비록 consumption은 모두 측정된 값이어도 같은 날짜의 다른 컬럼이 하나라도 nan이면 모두 버려지는 것이다.
이렇게 편집된 데이터를 df라는 다른 변수로 저장하였다.
df = data.dropna()
display(df)
데이터셋의 열의 개수가 2187 (4383-2196)로 거의 반으로 줄어들었다. 이것은 Nan을 포함하는 모든 열을 제거했기 때문이다.
print(id(df) == id(data))
# Output: False id 함수를 통해 df와 data가 메모리 주소값이 다른 변수라는 것을 확인한다.
Visualizing time series data
여기까지가 데이터를 다듬은 과정이었다. 이제는 데이터를 시각화해볼 수 있다. 두 가지 방법으로 그려볼 수 있다.
1. Matplotlib를 이용한 visualization
# visualization using matplotlib
import matplotlib.pyplot as plt
plt.rcParams.update({'font.size': 18}) # must set in top
plt.figure(figsize=(15,3))
plt.plot(df.Consumption, 'b', label='Consumption')
plt.plot(df.Wind, 'r', label='Wind')
plt.plot(df.Solar, 'g', label='Solar')
plt.plot(df['Wind+Solar'], 'orange', label='Wind+Solar')
plt.legend(loc='best', fontsize=10)
plt.show()

2. Pandas를 이용한 visualization
df.plot(figsize=(15,3), kind='line')
plt.legend(loc='best', fontsize=10)
plt.show()

위 두 그림을 통해 데이터가 시간에 따라 어떤 주기성을 보이며 변하고 있는 것을 볼 수 있다. 반면, Wind+Solar는 랜덤 하게 변하고 있는 것으로 보인다.
다음에는 데이터의 상관관계(correlation)와 자기 자신이 시간에 따라 어떻게 변하는지 보는 autocorrelation을 동일한 데이터에 대해서 측정해 보도록 하겠다.
'Programming > Time series forecasting' 카테고리의 다른 글
| 교차검증으로 최적의 시계열(time-series) 예측 모델 찾기 (ft. GridSearchCV) (1) | 2021.05.13 |
|---|---|
| (Data scientist 인터뷰) Time series forecasting 예제 (0) | 2021.05.09 |
| 시계열 모델의 교차검증 (cross-validation) 전략 (파이썬 코드 포함) (0) | 2021.05.04 |



댓글