[OpenCV] K-Means를 이용한 Image Segmentation(이미지 분할)
이미지 분할(segmentation) 은 컴퓨터 비전에서 물체를 인식하고 분리하는데 기초가 되는 중요한 이미지 처리 방법이다. 이번 포스팅에서는 K-Means clustering을 이용한 이미지 분할이 어떻게 이루어지는지 기초적인 예제를 통해 공부해 보도록 하겠다. K-Means Clustering를 지원하는 많은 라이브러리 중 OpenCV 를 이용하도록 하겠다.
1. Pre-test with a few points
알고리즘의 테스트를 위해 몇 개의 포인트로 이루어진 데이터에 대해서 OpenCV의 K-means clustering이 어떻게 작동하는지 테스트해보도록 하겠다. 다음의 12개의 좌표로 이루어진 데이터가 있다. 이 데이터의 차원은 (12, 2(x, y))가 될 것이다. 이 좌표들은 얼핏 보아도 세 개의 클러스터로 나눌 수 있는 것으로 보인다. 실제 알고리즘이 그렇게 찾는지 보도록 해보자.
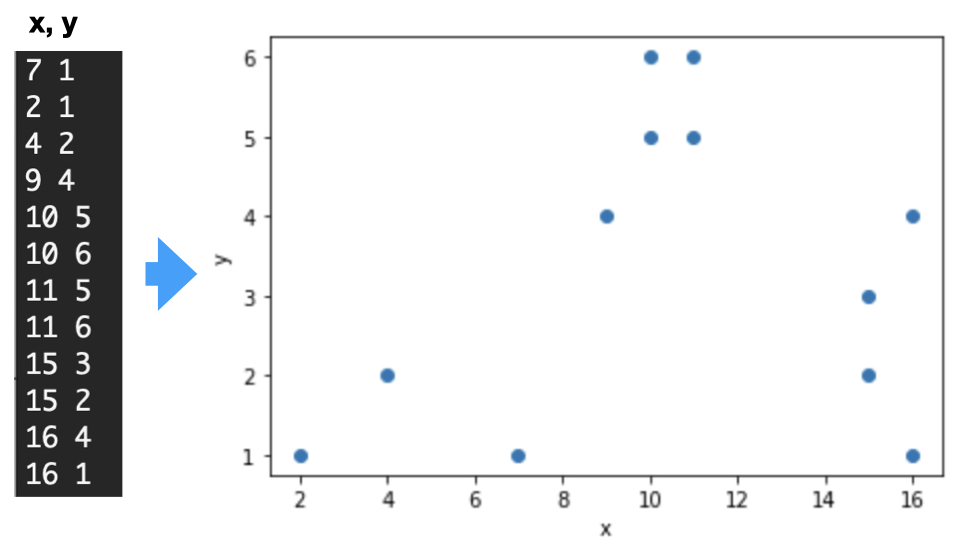
우선 필요한 모듈을 import 한다. cv2에 K-means함수가 포함되어 있다. matplotlib는 결과를 그리기 위해 로딩했다. 데이터를 읽어 numpy array로 저장한다.
import numpy as np
import os
import cv2
import matplotlib.pyplot as plt
다음은 좌표의 파일을 읽고 data 배열에 저장한다.
def __init__(self, Inputfile):
with open(Inputfile) as f:
lines = f.readlines()
row = len(lines)
col = len(lines[0].strip('\n').split())
self.data = np.empty((row, col))
k = 0
for l in lines:
arr = l.strip('\n').split()
for i in range(len(arr)):
self.data[k,i] = float(arr[i])
k +=1
실행하기 전에 알고리즘을 멈출 조건을 준다.
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
-
cv2.TERM_CRITERIA_EPS: epsilon으로 주어진 정확도를 만족하면 반복을 멈춘다.
-
cv2.TERM_CRITERIA_MAX_ITER: 정확도와 상관없이 미리 정해진 반복 횟수를 다 채우면 알고리즘을 멈춘다.
-
cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER : 위 둘 중 한 조건이 만족되면 멈춘다. 여기에서 max_iter=10, epsilon=1.0 으로 주었다
조건을 주었다면 알고리즘을 실행한다.
K = 3
attempts = 10
ret,label,center = cv2.kmeans(np.float32(self.data),K,
None,
criteria,
attempts,
cv2.KMEANS_RANDOM_CENTERS)
K는 데이터를 분류할 클러스터의 수이다. 이 예제에서는 3으로 주어 기대한대로 분류를 잘하는지 보도록 한다. attempts는 알고리즘의 실행 횟수이다. 10으로 주었다. 따라서 10번의 독립적인 실행으로 분류를 한 후 최적의 밀집도(compactness)를 가지는 결과를 리턴하게 될 것이다.
세 개의 output 변수가 있다.
-
ret: 밀집도(compactness)이다. 이것은 각 클러스터의 중심으로부터 거리제곱의 합이다.
-
labels: 각 점이 어느 클러스터에 속하게 되었는지 표시한다
-
centers: 클러스터의 중심 좌표를 리턴한다. K개의 데이터를 가진다.
다음과 같이 결과를 그려본다.
A = self.data[label.ravel()==0]
B = self.data[label.ravel()==1]
C = self.data[label.ravel()==2]
plt.scatter(A[:,0],A[:,1])
plt.scatter(B[:,0],B[:,1],c = 'r')
plt.scatter(C[:,0],C[:,1],c = 'g')
plt.scatter(center[:,0],center[:,1],s = 80,c = 'y', marker = 's')
plt.xlabel('x'),plt.ylabel('y')
plt.show()
예상대로 분류가 잘 된 것을 볼 수 있다.
2. Image segmentation using K-Means clustering with OpenCV
실제 이미지에 대한 K-Means clustering를 실행해 보도록 하겠다. 다음의 코드는 이미지를 읽고 K-means clustering을 진행하는 함수를 보여준다. 여기에서 주의해야 할 것은 cv2.kmeans에 입력하는 데이터는 반드시 float32 타입이어야 한다는 것이다. 변환하지 않고 입력하면 assertion error를 낼 것이다. 위의 예제에도 동일하게 적용된다.
class k_means:
def __init__(self):
original_image = cv2.imread("images/island.jpeg")
self.img = cv2.cvtColor(original_image,cv2.COLOR_BGR2RGB)
self.vectorized = self.img.reshape((-1,3))
self.vectorized = np.float32(self.vectorized)
def process(self, K):
criteria = (cv2.TERM_CRITERIA_EPS +
cv2.TERM_CRITERIA_MAX_ITER,10,1.0)
attempts = 10
ret,label,center = cv2.kmeans(self.vectorized,K,None,criteria,attempts,
cv2.KMEANS_PP_CENTERS)
center = np.uint8(center)
res = center[label.flatten()]
self.result_image = res.reshape((self.img.shape))
figure_size = 15
plt.figure(figsize=(figure_size,figure_size))
plt.subplot(1,2,1),plt.imshow(self.img)
plt.title('Original Image'), plt.xticks([]), plt.yticks([])
plt.subplot(1,2,2),plt.imshow(self.result_image)
plt.title('Segmented Image when K = %i' % K), plt.xticks([]), plt.yticks([])
plt.show()
위 코드에서 주목할 것은 process(self, K) 함수 안에 있는 cv2.kmeans 입력 변수에 클러스터 센터의 초기 위치를 KMEANS_PP_CENTERS라는 옵션이다. 이것은 위의 예제에서 사용한 랜덤 하게 초기 위치를 정하는 KMEANS_RANDOM_CENTERS와는 다른 방법이다.
이미지와 같이 데이터나 clustering의 복잡도가 높은 경우에는 초기 중심을 어떻게 주는냐에 따라 알고리즘의 성능이 크게 차이 나게 된다. 랜덤 하게 주면 중심을 찾지 못하고 소위 로컬 미니마에 갇히게 될 가능성이 높아진다. 이것은 clustering 알고리즘에서 잘 알려진 문제이며, 이것을 완화하는 조건이 K-Means++이다. 이것에 대한 자세한 내용은 아래의 링크를 참고하기 바란다.

Results
세 개의 다른 K =3,5,7 에 대해서 결과를 확인해 보도록 하자.



K가 증가할수록 이미지 컬러의 세분화가 증가하는 것을 알수있다. 이미지에서 clustering은 비슷한 픽셀 값을 가지는 것들을 분류하는 것이다. 따라서 클러스터 개수가 늘어날수록 이미지 내의 물체를 세밀하게 구분할 수 있게 된다.
이 포스팅에서는 computer vision의 가장 중요한 기술인 이미지 분할에 대해서 공부해보았다. 특히, OpenCV에서 제공하는 k-means clustering을 이용해서 이미지의 컬러를 구분하는 것을 해보았다. 이것을 기초로 다음 포스팅에는 머신러닝을 이용한 이미지 분할에 대해서 알아보도록 하겠다.
참고 링크
OpenCV: K-Means Clustering in OpenCV
Goal Learn to use cv.kmeans() function in OpenCV for data clustering Understanding Parameters Input parameters samples : It should be of np.float32 data type, and each feature should be put in a single column. nclusters(K) : Number of clusters required at
docs.opencv.org
k-평균 알고리즘 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. k-평균 알고리즘(K-means algorithm)은 주어진 데이터를 k개의 클러스터로 묶는 알고리즘으로, 각 클러스터와 거리 차이의 분산을 최소화하는 방식으로 동작한다. 이
ko.wikipedia.org
'Programming > Computer Vision' 카테고리의 다른 글
| FFMPEG로 다양한 input-output 소스 스트리밍하기 (option 설명 포함) (0) | 2021.10.23 |
|---|---|
| [OpenCV] 이미지 이진화(Image binarization)를 이용한 image segmentation (Python) (0) | 2021.06.28 |
| [OpenCV] Image Edge Enhancement: 라플라스 연산자 (Laplace Operator)-파이썬 코드 포함 (0) | 2020.11.04 |
| [OpenCV] 이미지 경계선 강화: DoG - 파이썬 코드 포함 (0) | 2020.11.04 |
| [OpenCV] 이미지 경계선 강화: Unsharp 필터 - 파이썬 코드 포함 (0) | 2020.11.04 |




댓글